FWIW restic repository format already has two independent implementations. Restic (in Go) and Rustic (Rust), so the chances of both going unmaintained is hopefully pretty low.
- 0 Posts
- 50 Comments
Joined 1 year ago
Cake day: June 27th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
Let me be more clear: devs are not required to release binaries at all. Bit they should, if they want their work to be widely used.
Yeah, but that’s not there reality of the situation. Docker images is what drives wide adoption. Docker is also great development tool if one needs to test stuff quickly, so the Dockerfile is there from the very beginning and thus providing image is almost for free.
Binaries are more involved because suddenly you have multiple OSes, libc, musl,… it’s not always easy to build statically linked binary (and it’s also often bad idea) So it’s much less likely to happen. If you tried just running statically linked binary on NixOS, you probably know it’s not as simple as
chmod a+x.I also fully agree with you that curl+pipe+bash random stuff should be banned as awful practice and that is much worse than containers in general. But posting instructions on forums and websites is not per se dangerous or a bad practice. Following them blindly is, but there is still people not wearing seatbelts in cars or helmets on bikes, so…
Exactly what I’m saying. People will do stupid stuff and containers have nothing to do with it.
Chmod 777 should be banned in any case, but that steams from containers usage (due to wrongly built images) more than anything else, so I guess you are biting your own cookie here.
Most of the time it’s not necessary at all. People just have “allow everything, because I have no idea where the problem could be”. Containers frequently run as root, so I’d say the chmod is not necessary.
In a world where containers are the only proposed solution, I believe something will be taken from us all.
I think you mean images not containers? I don’t think anything will be taken, image is just easy to provide, if there is no binary provided, there would likely be no binary even without docker.
In fact IIRC this practice of providing binaries is relatively new trend. (Popularized by Go I think) Back in the days you got source code and perhaps Makefile. If you were lucky a debian/src directory with code to build your package. And there was no lack of freedom.
On one hand you complain about docker images making people dumb on another you complain about absence of pre-compiled binary instead of learning how to build stuff you run. A bit of a double standard.
I don’t agree with the premise of your comment about containers. I think most of the downsides you listed are misplaced.
First of all they make the user dumber. Instead of learning something new, you blindly “compose pull & up” your way. Easy, but it’s dumbifier and that’s not a good thing.
I’d argue, that actually using containers properly requires very solid Linux skills. If someone indeed blindly “compose pull & up” their stuff, this is no different than blind
curl | sudo bashwhich is still very common. People are going to muddle through the installation copy pasting stuff no matter what. I don’t see why containers and compose files would be any different than pipe to bash or random reddit comment with “step by step instructions”. Look at any forum where end users aren’t technically strong and you’ll see the same (emulation forums, raspberry pi based stuff, home automation,…) - random shell scripts,rm -rf this ; chmod 777 thatContainers are just another piece of software that someone can and will run blindly. But I don’t see why you’d single them out here.
Second, there is a dangerous trend where projects only release containers, and that’s bad for freedom of choice
As a developer I can’t agree here. The docker images (not “containers” to be precise) are not there replacing deb packages. They are there because it’s easy to provide image. It’s much harder to release a set of debs, rpms and whatnot for distribution the developer isn’t even using. The other options wouldn’t even be there in the first place, because there’s only so many hours in a day and my open source work is not paying my bills most of the time. (patches and continued maintenance is of course welcome) So the alternative would be just the source code, which you still get. No one is limiting your options there. If anything the Dockerfile at least shows exactly how you can build the software yourself even without using docker. It’s just bash script with extra isolation.
I am aware that you can download an image and extract the files inside, that’s more an hack than a solution.
Yeah please don’t do that. It’s probably not a good idea. Just build the binary or whatever you’re trying to use yourself. The binaries in image often depend on libraries inside said image which can be different from your system.
Third, with containers you are forced to use whatever deployment the devs have chosen for you. Maybe I don’t want 10 postgres instances one for each service, or maybe I already have my nginx reverse proxy or so.
It might be easier (effort-wise) but you’re certainly not forced. At the very least you can clone the repo and just edit the Dockerfile to your liking. With compose file it’s the same story, just edit the thing. Or don’t use it at all. I frequently use compose file just for reference/documentation and run software as a set of systemd units in Nix. You do you. You don’t have to follow a path that someone paved if you don’t like the destination. Remember that it’s often someone’s free time that paid for this path, they are not obliged to provide perfect solution for you. They are not taking anything away from you by providing solution that someone else can use.
I’m huge fan of Nix, but for someone wondering if they should “learn docker” Nix is absolutely brutal.
Also IMO while there’s some overlap, one is not a complete replacement for the other. I use both in combination frequently.

 8·4 months ago
8·4 months agoI’m curious. How would you identify who’s guest and who’s not in this case?
With multiple networks it’s pretty easy as they are on a different network.
I have a bunch of these myself and that is my experience, but don’t have any screenshots now.
However there’s great comparison of these thin clients if you don’t mind Polish: https://www.youtube.com/watch?v=DLRplLPdd3Q
Just the relevant screens to save you some time:
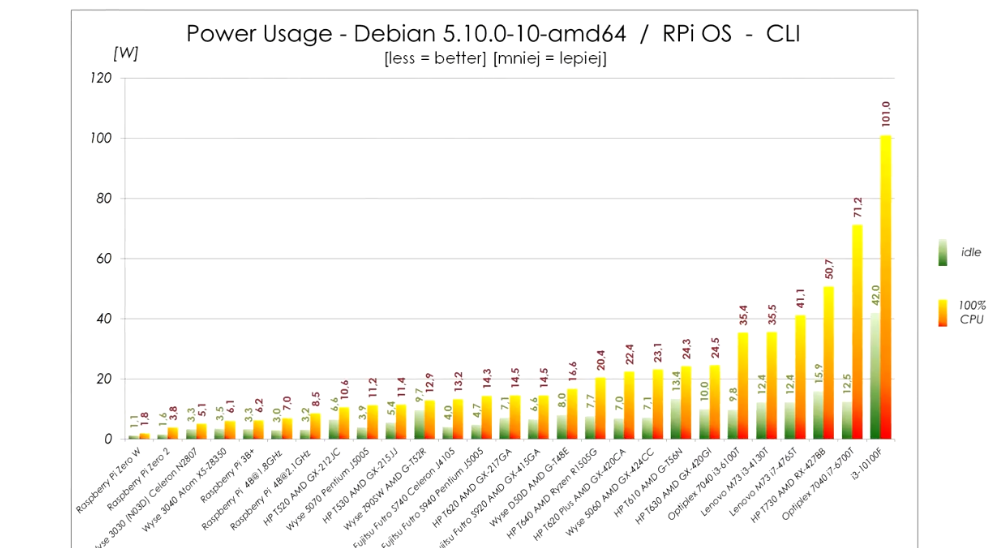
Power usage:
Cinebench multi core:
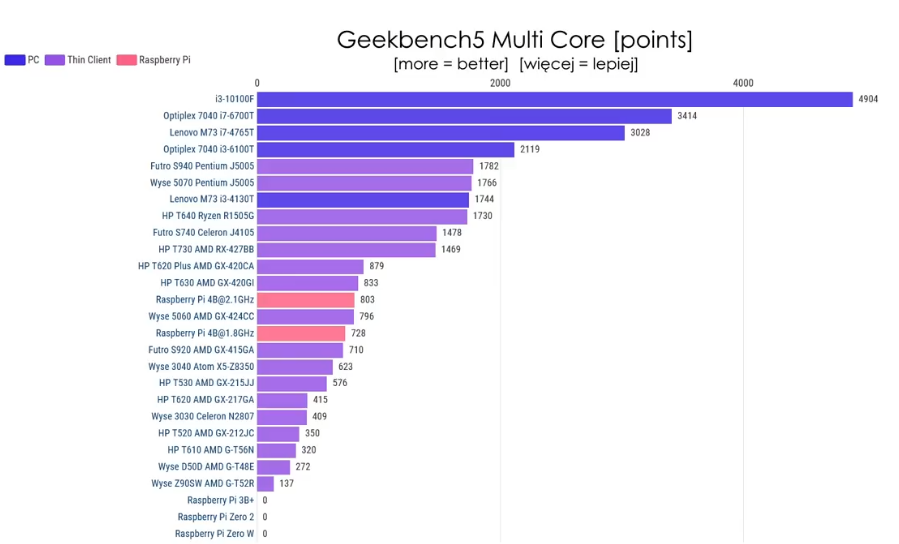
The power usage in idle is within 2W from Pi 4 and the performance is about double compared to overclocked Pi 4. It’s really quite viable alternative unless you need really small device. The only alternative size-wise is slightly bigger WYSE 3040, but that one has x5-z8350 CPU, which sits somewhere between Pi3B+ and Pi4 performance-wise. It is also very low power though and if you don’t need that much CPU it is also very viable replacement. (these can be easily bought for about €60 on eBay, or cheaper if you shop around)
Also each W of extra idle power is about 9kWh extra consumed. Even if you paid 50c/kWh (which would be more than I’ve ever seen) that’s €5 per year extra. So I wouldn’t lose my sleep over 2W more or less. Prices here are high, 9kWh/y is rounding error.
Thin clients based on J5005 or J4105 generally idle under 5W. (Futro S740, Wyse 5070,…) They consume a bit more when 100% loaded (11W vs 8W), but they also provide about 2x performance of Pi4.
(That article you shared is measuring power consumption on the USB port, which does not take into account overhead of USB adapter itself)
If you search ebay for Intel based thin clients, many are more powerful than RPi while being passively cooled and having very similar power consumption.
 0·5 months ago
0·5 months agoYou always get a Result. On that result you can call
result.unwrap()(give me the bool or crash) orresult.unwrap_or_default()(give me bool orfalseif there was error) or any other way you can think of. The point is that Rust won’t let you get value out of that Result until you somehow didn’t handle possible failure. If function does not return Result and returns just value directly, you (as a function caller) are guaranteed to always get a value, you can rely on there not being a failure that the function didn’t handle internally.
Well in that sense Rust is even more predictable than Java. In Java you can always get back exception that bubbled up the stack. Rust function would in that case return Result that you need to handle somehow before getting the value.
Predictable in what sense?
 1·7 months ago
1·7 months agoI wish I had time and domain knowledge to add those two to Solvespace. It’s the only thing that I’m really missing. And for 3D printing design chamfers are really necessary, the models print much nicer when there are no sharp corners.
 1·8 months ago
1·8 months agoYou can’t do much about users that just don’t care. But more technically inclined folks often do care and these are the people that develop the web and maintain the computer/browser for other people.
A lot of folks in my circle use chrome, but the moment the AdBlock plugin stops working they’ll likely switch to anything that works better. They are not necessarily too concerned about privacy, but they also don’t want to have most of their browsing made effectively impossible by ads everywhere.
I mean, just try and use the web without any sort of blocking. A lot of sites don’t even have their content visible.
Yeah, I was saying “no reason” in the context of SAAS. Once the management falls on the end user, it’s a different beast altogether.
I think we’re trying to say the same in a different way actually. 😅
“If” being the key word here. There are nuances to be considered. One DB might run really well on arm, the other not so much.
I’m saying it as huge fan of the arm servers. They are amazing and often save a lot of money essentially for free. (practically only a few characters change in terraform) In AWS with the hosted services (Opensearch, and such) there’s usually no good reason to pay extra for x86 hardware especially since most of the intricacies are handled by AWS.
But there are workloads that just do not run on arm all that well and you would end up paying more for the HW to get to the performance levels you had with x86.
And that’s beside all those little pain points mentioned above that you’re “left to deal with” which isn’t cheap either. (but that doesn’t show up on the AWS bill, so management is happy to report cost savings)
Laws across Europe are not uniform. Last time I’ve checked, there were a couple of countries where downloading for personal use was not illegal.
IIRC Spain, Poland were such countries? Maybe Switzerland? That’s on top of countries where it’s technically illegal but not enforced.
There are probably more countries around the world with similar laws or with no laws regulating downloads. But I’m on my phone so can’t look it up.
Feel free to correct me.
I think their point was that there are countries where piracy (or circumventing copy protection) isn’t illegal and only copyright laws exist. Thus downloading pirated stuff isn’t inherently illegal.
In some countries the copy protection removal isn’t dealt with in any way and thus it’s not inherently forbidden, in some it’s actually outright permitted by law in some situations. (personal use, education,…) Same applies to tools for copy protection circumvention.
In Tailscale you can set up an exit node which lets you access the entire internet via its internet connection.
You could set up an exit node that would let you access the internet via some (anonymizing) VPN providers like Mullvad or any other.
This sounds like Tailscale is simply setting up this exit node for Mullvad on their side and providing it as a service. So it’s not like using another VPN anonymizers is impossible, it’s just convenient to use Mullvad.
RAID is not backup. RAID is used for increased capacity, throughput or uptime. (Depending on configuration)
Multiple volumes would likely get corrupted just as much with faulty RAM as RAID would. Besides RAM there’s controller, CPU, power supply and possibly more single points of failure in that NAS, that would destroy both RAID and multiple volumes.
So assuming you have external backup, I’d go with RAID for better uptime as opposed to some custom multi volume pseudo-RAID for the same.
AFAIK Glacier is unlikely to be tape based. A bunch of offline drives is more realistic scenario. But generally it’s not public knowledge unless you found some trustworthy source for the tape theory?